
When platform golden path leads back to ops
Platform Engineering is one of the most compelling ideas in modern software delivery. The promise is genuinely beautiful: golden paths, self-service environments, paved roads, less cognitive load, safer deployments, and developers who can finally ship without first obtaining a PhD in Kubernetes, networking and a minor in cloud IAM philosophy.
Done well, it is excellent. Done poorly, it is the Ops team from 2014 wearing a hoodie and carrying a Backstage login page.
The pattern is depressingly predictable. A company does the Agile transformation. Then DevOps. Then the cloud migration. Developers gain operational responsibility. Complexity grows. Teams drown in YAML, IAM policies, and existential questions about Terraform state locking. Someone proposes a platform team to absorb the shared burden. The platform ships. Developers lose operational context. The platform team becomes a bottleneck. We have arrived back where we started, just with a portal instead of ServiceNow and a roadmap instead of a ticket queue.
This is not inevitable, but it is common enough that we should talk about why it keeps happening and what the alternative looks like.
The organizational gravity toward centralization
There is a gravitational pull in every large organization toward centralization. It shows up disguised as efficiency, consistency, governance, or cost control. Platform Engineering is particularly susceptible because the economic argument is strong: why should 40 teams each solve deployment, observability, and secrets management independently?
They should not. That much is obvious.
But the leap from “shared capabilities” to “centralized control” is shorter than most architecture diagrams suggest. The moment a platform team controls the deployment pipeline, owns the runtime configuration, manages the observability stack, and gates access to production environments, it has accumulated the same power an Ops team held in 2012. The difference is cosmetic. The Slack channel is friendlier. The bottleneck is identical.
The failure is not in building a platform. It is in building one that concentrates operational knowledge rather than distributing it.
Three symptoms that reveal a platform has become a silo
How do you know when your platform has crossed the line? I look for three concrete symptoms.

Symptom one: incident response becomes a spectator sport. When something breaks, the application team opens a bridge call and waits. They cannot interpret the dashboards the platform provides. They do not know which deployment configuration affects their latency. They cannot distinguish between a platform failure and a failure in their own code. They are dependent, not empowered.
Symptom two: the platform backlog becomes a blocking queue. Teams need a capability. The platform does not support it yet. There is no escape hatch, no documented way to self-serve outside the golden path. The request enters a backlog. Weeks pass. The team either waits or builds a shadow system in a folder named “temporary-workaround-do-not-delete.” Both outcomes are toxic.
Symptom three: production knowledge concentrates instead of spreading. Six months after platform adoption, fewer engineers understand how their services run in production than before. The platform absorbed that knowledge without redistributing it. If you ask a developer what happens when their service’s primary database becomes unreachable, and they say “the platform handles that,” you have a problem.
Why cognitive load is the wrong framing when used alone
The Team Topologies argument for platforms centers on cognitive load: reduce it for stream-aligned teams so they can focus on delivering business value. This is correct as far as it goes. But cognitive load reduction is a means, not an end.
The end is reliable, fast delivery of software that serves users well. Cognitive load reduction serves that goal only when it removes incidental complexity, the stuff that is arbitrary, inconsistent, or duplicated. It actively harms the goal when it removes essential complexity, the understanding required to operate, debug, and evolve a system.
A developer does not need to understand the internal implementation of the service mesh control plane. That is incidental. A developer absolutely needs to understand that their service communicates over a mesh, that retries are configured at the mesh layer, that timeouts cascade, and that a misbehaving dependency can amplify load through automatic retries. That is essential.

The distinction between incidental and essential complexity should drive every platform design decision. Most platform teams get this wrong not because they are careless, but because the boundary is contextual, shifts as teams grow more capable, and nobody wrote it down before the original architect left to become a DevRel.
The production contract: what a healthy platform actually looks like
A platform that avoids becoming a silo makes its contract explicit and visible. Here is what I mean by that.
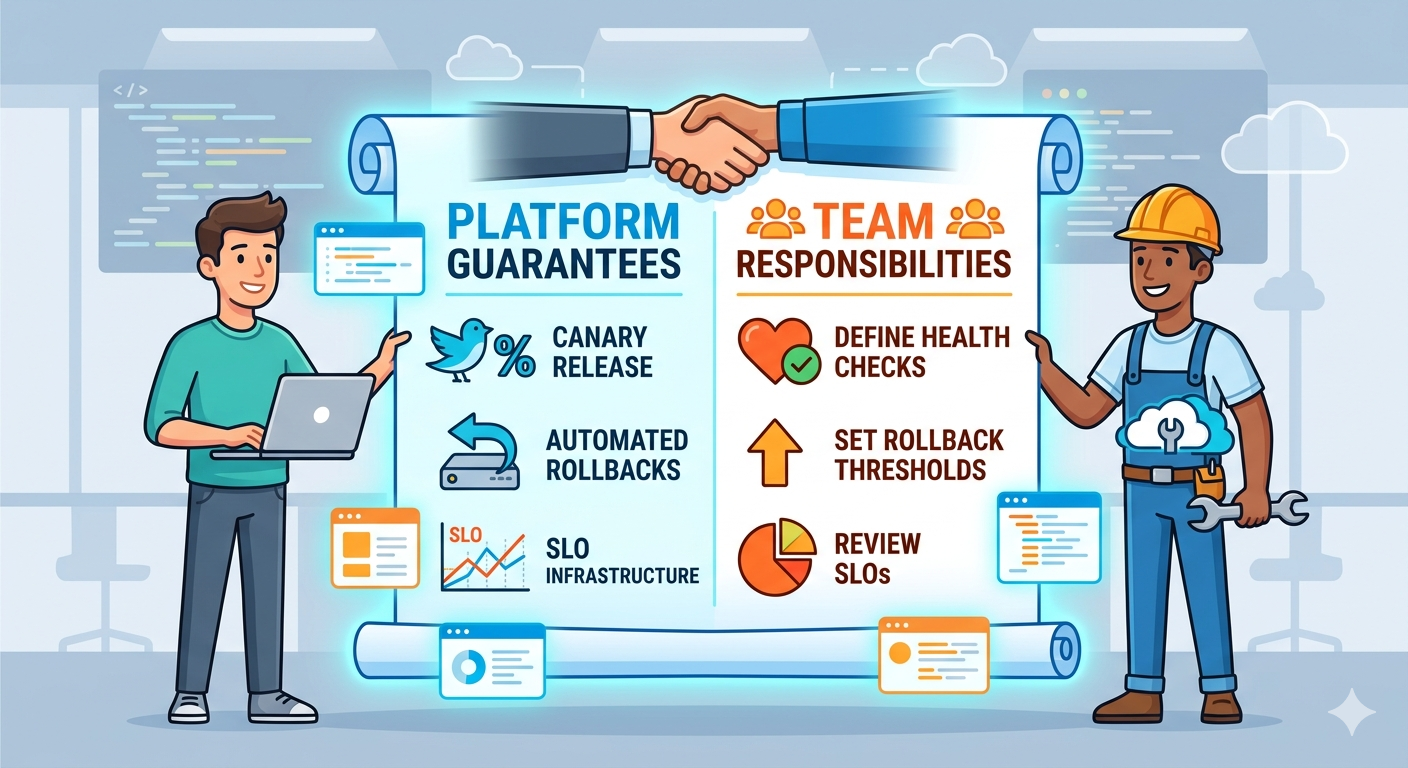
Every capability the platform provides should come with a clear statement of what the platform guarantees and what the consuming team remains responsible for. Not a legal document. A living, visible interface in the same place developers interact with the platform daily.
For deployment: the platform guarantees canary analysis, automated rollback on error-rate breach, and blue-green traffic shifting. The team is responsible for defining health checks, setting rollback thresholds appropriate to their SLO, and understanding what “healthy” means for their service.
For observability: the platform guarantees metrics collection, log aggregation, and distributed tracing infrastructure. The team is responsible for instrumenting business-critical paths, defining meaningful SLIs, reviewing dashboards during development (not only during incidents), and maintaining alert hygiene.
For runtime: the platform guarantees autoscaling, secret injection, and network policy enforcement. The team is responsible for load testing, understanding their resource profile under peak traffic, and documenting failure modes for their dependencies.
This contract model forces both sides to stay engaged. The platform cannot drift toward “we handle everything” because the contract makes boundaries explicit. The application team cannot drift toward “we just write code” because the contract makes their operational responsibilities visible.
Five design principles that prevent silo formation
Based on platforms I have seen succeed and fail, these principles separate enabling platforms from controlling ones:
1. Escape hatches are first-class features. A golden path is only golden if teams can leave it when necessary. The platform should document how to diverge, what operational cost that carries, and what support changes. If divergence is impossible, you have built a cage.
2. Observability is educational, not just functional. Dashboards should teach engineers how their system behaves, not just display numbers. Annotate defaults. Explain what normal looks like. Link to runbooks from alert definitions. Every dashboard is a learning opportunity or a source of confusion.
3. Incident participation is non-negotiable for platform teams. Not owning every incident. Participating in enough of them to understand how abstractions fail in practice. A platform team that never sees its users struggle will build increasingly irrelevant abstractions.
4. Adoption is earned, not mandated. Mandatory adoption hides quality problems. If teams are forced to use the platform, you lose the signal that tells you whether it is actually good. Voluntary adoption with strong incentives (speed, safety, less toil) is harder to achieve and far more durable.
5. Success is measured by team capability, not platform usage. The metric that matters is whether application teams can deliver and operate their services with increasing independence over time. If platform adoption rises while team operational capability declines, the platform is creating dependency.
SLOs as the shared language between platform and product
Service Level Objectives solve a coordination problem that no amount of documentation or ticket workflows can address. They create a shared definition of “good enough” that both the platform and the application team can reference.
When a platform provides SLO tooling (dashboards, error budget tracking, burn-rate alerts) it gives application teams a framework for reasoning about reliability without requiring them to build that framework from scratch. When application teams actually define and use SLOs, they maintain a connection to production reality regardless of how much the platform abstracts.

The key insight from Google’s SRE practice is that SLOs create joint accountability. The platform team cares about SLO achievement because platform failures affect it. The application team cares because application failures affect it. Neither side can point fingers without looking at the same number.
Without SLOs, reliability conversations devolve into opinion. “The platform is flaky.” “Your code is inefficient.” “It worked in staging.” With SLOs, the conversation becomes data-driven. “We burned 40% of our monthly error budget in two hours. The traces show retry amplification at the ingress layer. Let’s look at both the platform retry config and the application timeout settings.”
That is collaborative engineering. Not a silo. Not blame. Engineering.
The cultural prerequisite nobody wants to discuss
No platform architecture survives contact with a blame-oriented culture.
If the organization punishes failure, teams will optimize for plausible deniability. Developers will prefer the platform to own production because ownership means exposure. Platform teams will prefer strict controls because flexibility means risk. Everyone will prefer thick boundaries because thick boundaries protect individuals at the expense of the system.

A platform in a healthy culture becomes an accelerator. Teams use it because it makes them faster and safer. They understand its boundaries because they helped define them. They contribute back because the relationship is collaborative.
A platform in a fear-driven culture becomes a shield. Teams use it to transfer blame. They avoid understanding it because understanding implies responsibility. They never contribute back because the relationship is transactional.
Same technology. Same architecture. Completely different outcomes.
This is why I am skeptical of purely technical solutions to the platform silo problem. You can design the most elegant capability model, the most transparent production contract, the most educational observability layer. None of it will matter if the organizational incentives push people toward isolation rather than collaboration.
A litmus test for your platform

Here is the question I ask every platform team I work with:
If your platform disappeared tomorrow and teams had to operate their services directly, how long would it take them to recover?
If the answer is “days, maybe a week, while they re-learn tools and rebuild pipelines” then that is healthy. The platform was saving them time, not hiding reality from them.
If the answer is “they could not, because they do not know how their services run in production” then the platform has become a single point of organizational failure. It is not enabling teams. It is anesthetizing them.
The goal of Platform Engineering was never to make production invisible. It was to make production approachable. Those are very different things, and the distance between them is where platforms either succeed as force multipliers or fail as rebranded operations teams with better slide decks.
Build platforms that make engineers more capable, not more dependent. Everything else follows from that. And if your platform still requires six Slack channels, three approvals, and a senior engineer named Dave to deploy a config change, congratulations: you have built Ops-as-a-Service. Please enjoy your golden ticket queue.